您现在的位置是:网站首页> 编程资料编程资料
.NET Core 实现定时抓取网站文章并发送到邮箱_实用技巧_
![]() 2023-05-24
423人已围观
2023-05-24
423人已围观
简介 .NET Core 实现定时抓取网站文章并发送到邮箱_实用技巧_
前言
大家好,我是晓晨。许久没有更新博客了,今天给大家带来一篇干货型文章,一个每隔5分钟抓取博客园首页文章信息并在第二天的上午9点发送到你的邮箱的小工具。比如我在2018年2月14日,9点来到公司我就会收到一封邮件,是2018年2月13日的博客园首页的文章信息。写这个小工具的初衷是,一直有看博客的习惯,但是最近由于各种原因吧,可能几天都不会看一下博客,要是中途错过了什么好文可是十分心疼的哈哈。所以做了个工具,每天归档发到邮箱,妈妈再也不会担心我错过好的文章了。为什么只抓取首页?因为博客园首页文章的质量相对来说高一些。
准备
作为一个持续运行的工具,没有日志记录怎么行,我准备使用的是NLog来记录日志,它有个日志归档功能非常不错。在http请求中,由于网络问题吧可能会出现失败的情况,这里我使用Polly来进行Retry。使用HtmlAgilityPack来解析网页,需要对xpath有一定了解。下面是详细说明:
| 组件名 | 用途 | github |
|---|---|---|
| NLog | 记录日志 | https://github.com/NLog/NLog |
| Polly | 当http请求失败,进行重试 | https://github.com/App-vNext/Polly |
| HtmlAgilityPack | 网页解析 | https://github.com/zzzprojects/html-agility-pack |
| MailKit | 发送邮件 | https://github.com/jstedfast/MailKit |
有不了解的组件,可以通过访问github获取资料。
参考文章
https://www.jb51.net/article/112595.htm
获取&解析博客园首页数据
我是用的是HttpWebRequest来进行http请求,下面分享一下我简单封装的类库:
using System; using System.IO; using System.Net; using System.Text; namespace CnBlogSubscribeTool { /// /// Simple Http Request Class /// .NET Framework >= 4.0 /// Author:stulzq /// CreatedTime:2017-12-12 15:54:47 /// public class HttpUtil { static HttpUtil() { //Set connection limit ,Default limit is 2 ServicePointManager.DefaultConnectionLimit = 1024; } /// /// Default Timeout 20s /// public static int DefaultTimeout = 20000; /// /// Is Auto Redirect /// public static bool DefalutAllowAutoRedirect = true; /// /// Default Encoding /// public static Encoding DefaultEncoding = Encoding.UTF8; /// /// Default UserAgent /// public static string DefaultUserAgent = "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36" ; /// /// Default Referer /// public static string DefaultReferer = ""; /// /// httpget request /// /// Internet Address /// string public static string GetString(string url) { var stream = GetStream(url); string result; using (StreamReader sr = new StreamReader(stream)) { result = sr.ReadToEnd(); } return result; } /// /// httppost request /// /// Internet Address /// Post request data /// string public static string PostString(string url, string postData) { var stream = PostStream(url, postData); string result; using (StreamReader sr = new StreamReader(stream)) { result = sr.ReadToEnd(); } return result; } /// /// Create Response /// /// /// Is post Request /// Post request data /// /// http get request /// /// /// Response Stream public static Stream GetStream(string url) { var stream = CreateResponse(url, false).GetResponseStream(); if (stream == null) { throw new Exception("Response error,the response stream is null"); } else { return stream; } } /// /// http post request /// /// /// post data /// Response Stream public static Stream PostStream(string url, string postData) { var stream = CreateResponse(url, true, postData).GetResponseStream(); if (stream == null) { throw new Exception("Response error,the response stream is null"); } else { return stream; } } } }获取首页数据
string res = HttpUtil.GetString(https://www.cnblogs.com);
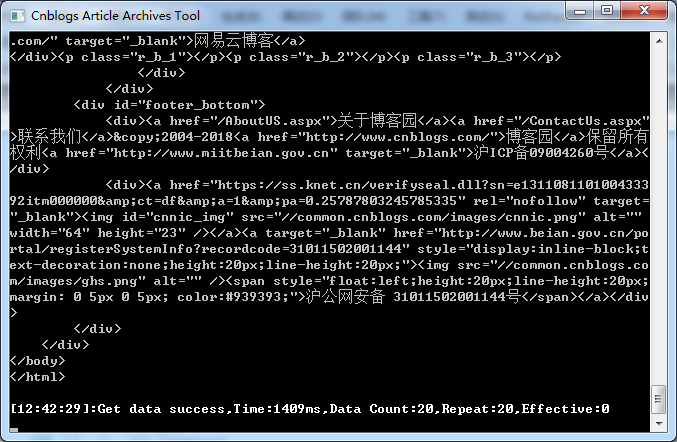
解析数据
我们成功获取到了html,但是怎么提取我们需要的信息(文章标题、地址、摘要、作者、发布时间)呢。这里就亮出了我们的利剑HtmlAgilityPack,他是一个可以根据xpath来解析网页的组件。
载入我们前面获取的html:
HtmlDocument doc = new HtmlDocument(); doc.LoadHtml(html);
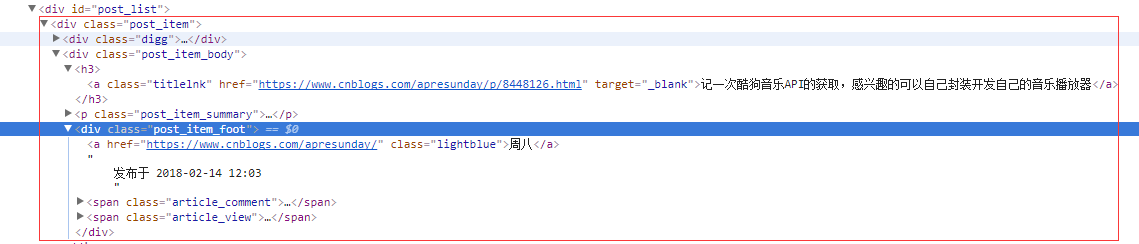
从上图中,我们可以看出,每条文章所有信息都在一个class为post_item的div里,我们先获取所有的class=post_item的div
//获取所有文章数据项 var itemBodys = doc.DocumentNode.SelectNodes("//div[@class='post_item_body']");我们继续分析,可以看出文章的标题在class=post_item_body的div下面的h3标签下的a标签,摘要信息在class=post_item_summary的p标签里面,发布时间和作者在class=post_item_foot的div里,分析完毕,我们可以取出我们想要的数据了:
foreach (var itemBody in itemBodys) { //标题元素 var titleElem = itemBody.SelectSingleNode("h3/a"); //获取标题 var title = titleElem?.InnerText; //获取url var url = titleElem?.Attributes["href"]?.Value; //摘要元素 var summaryElem = itemBody.SelectSingleNode("p[@class='post_item_summary']"); //获取摘要 var summary = summaryElem?.InnerText.Replace("\r\n", "").Trim(); //数据项底部元素 var footElem = itemBody.SelectSingleNode("div[@class='post_item_foot']"); //获取作者 var author = footElem?.SelectSingleNode("a")?.InnerText; //获取文章发布时间 var publishTime = Regex.Match(footElem?.InnerText, "\\d+-\\d+-\\d+ \\d+:\\d+").Value; Console.WriteLine($"标题:{title}"); Console.WriteLine($"网址:{url}"); Console.WriteLine($"摘要:{summary}"); Console.WriteLine($"作者:{author}"); Console.WriteLine($"发布时间:{publishTime}"); Console.WriteLine("--------------华丽的分割线---------------"); }运行一下:
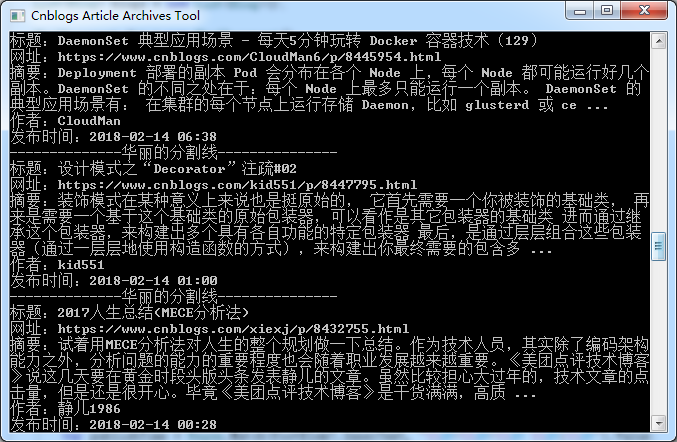
我们成功的获取了我们想要的信息。现在我们定义一个Blog对象将它们装起来。
public class Blog { /// /// 标题 /// public string Title { get; set; } /// /// 博文url /// public string Url { get; set; } /// /// 摘要 /// public string Summary { get; set; } /// /// 作者 /// public string Author { get; set; } /// /// 发布时间 /// public DateTime PublishTime { get; set; } }http请求失败重试
我们使用Polly在我们的http请求失败时进行重试,设置为重试3次。
//初始化重试器 _retryTwoTimesPolicy = Policy .Handle() .Retry(3, (ex, count) => { _logger.Error("Excuted Failed! Retry {0}", count); _logger.Error("Exeption from {0}", ex.GetType().Name); });
测试一下:
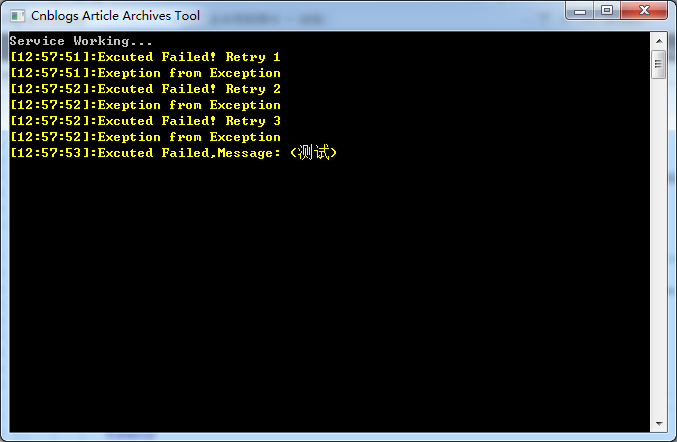
可以看到当遇到exception是Polly会帮我们重试三次,如果三次重试都失败了那么会放弃。
发送邮件
使用MailKit来进行邮件发送,它支持IMAP,POP3和SMTP协议,并且是跨平台的十分优秀。下面是根据前面园友的分享自己封装的一个类库:
using System.Collections.Generic; using CnBlogSubscribeTool.Config; using MailKit.Net.Smtp; using MimeKit; namespace CnBlogSubscribeTool { /// /// send email /// public class MailUtil { private static bool SendMail(MimeMessage mailMessage,MailConfig config) { try { var smtpClient = new SmtpClient(); smtpClient.Timeout = 10 * 1000; //设置超时时间 smtpClient.Connect(config.Host, config.Port, MailKit.Security.SecureSocketOptions.None);//连接到远程smtp服务器 smtpClient.Authenticate(config.Address, config.Password); smtpClient.Send(mailMessage);//发送邮件 smtpClient.Disconnect(true); return true; } catch { throw; } } /// ///发送邮件 /// /// 配置 /// 接收人 /// 发送人 /// 标题 /// 内容 /// 附件 /// 附件名 /// receives, string sender, string subject, string body, byte[] attachments = null,string fileName="") { var fromMailAddress = new MailboxAddress(config.Name, config.Address); var mailMessage = new MimeMessage(); mailMessage.From.Add(fromMailAddress); foreach (var add in receives) { var toMailAddress = new MailboxAddress(add); mailMessage.To.Add(toMailAddress); } if (!string.IsNullOrEmpty(sender)) { var replyTo = new MailboxAddress(config.Name, sender); mailMessage.ReplyTo.Add(replyTo); } var bodyBuilder = new BodyBuilder() { HtmlBody = body }; //附件 if (attachments != null) { if (string.IsNullOrEmpty(fileName)) { fileName = "未命名文件.txt"; } var attachment = bodyBuilder.Attachments.Add(fileName, attachments); //解决中文文件名乱码 var charset = "GB18030"; attachment.ContentType.Parameters.Clear(); attachment.ContentDisposition.Parameters.Clear(); attachment.ContentType.
相关内容
- 详解Asp.net web.config customErrors 如何设置_实用技巧_
- XAML: 自定义控件中事件处理的最佳实践方法_实用技巧_
- ASP.NET没有魔法_ASP.NET MVC 模型验证方法_实用技巧_
- .Net Core部署到CentOS的图文教程_实用技巧_
- .net Core连接MongoDB数据库的步骤详解_实用技巧_
- ASP.NET Core缓存静态资源示例详解_实用技巧_
- mysql安装后.net程序运行出错的解决方法_实用技巧_
- ASP.NET Core 2.0中Razor页面禁用防伪令牌验证_实用技巧_
- .NET中OpenFileDialog使用线程报错的解决方法_实用技巧_
- MongoDB.Net工具库MongoRepository使用方法详解_实用技巧_
点击排行
本栏推荐